
概要
2月になりました。
2月といえば中学受験です。関東圏ではこれからが本番ですが、関西圏では一足先に山場を越えたようです。
その中でも最難関を誇る灘中の入試問題が、最近SNSで流れてきて目に留まりました。
その名も「漢字しりとり」
偏差値71の灘中出題「漢字しりとり」が話題…大人も解けない難問をスイスイ攻略する子の親が実践する家庭教育 「法(A)」「(A)注」「注(B)」「(B)角」「角(C)」「(C)胸」…ABCの字で三字熟語作れ | PRESIDENT Online(プレジデントオンライン)
president.jp
ざっくり説明しますと、二字熟語の前後が同じ漢字を繋いだ文字列が与えられ、繋いだ部分が隠されています。いくつかのヒントから隠された三字熟語を回答する、という問題です。

実際の問題はリンク先でご確認下さい。
さて、この漢字しりとり解いてみて非常に面白かったので、もっとたくさん作れないかなと筆者は思いました。
最初はChatGPTやBingAIにルールを細かく指定して、AIに考えさせましたが、何度やっても『存在しない熟語』でそれっぽくしりとりを繋いできたりしたので、最終的に「ここまでのプロンプト試行錯誤をする間に、作問ロジックはもう脳内にあるので、もうPython書いたほうが早くて確実」と思い、作りました。(AIにはコーディング補助してもらいました)
ちょっと書き換えるだけで四字熟語版も作れるので、よかったら試してみて下さい。
もし「このコード変じゃない?」「こうしたらもっと良くなる」というご意見があったらツッコミ歓迎です。
最後に、実際に存在する熟語のデータセットとして(コード中のjyukugo_list.txt)下記の研究を使わせていただきました。
この場を借りて感謝を述べさせていただきます。ありがとうございました。
Tamaoka, K., Makioka, S., Sanders, S. & Verdonschot, R.G. (2017). www.kanjidatabase.com: A new interactive online database for psychological and linguistic research on Japanese kanji and their compound words. Psychological Research. 81, 696-708.
www.kanjidatabase.com
Pythonで書いてみた
さて本編です。
動かすにはメインとなるPythonファイルと、jyukugo_list.txtという二字熟語が改行で記録されているテキストファイルを同じディレクトリに置いておきます。
jyukugo_list.txtは、上記リンクの熟語データベースhttps://www.kanjidatabase.com/jukugo_database.php からコピペして作っています。
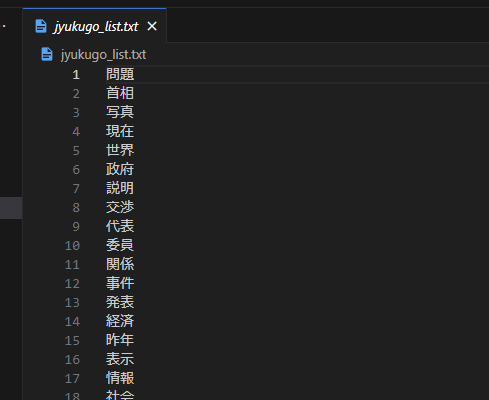
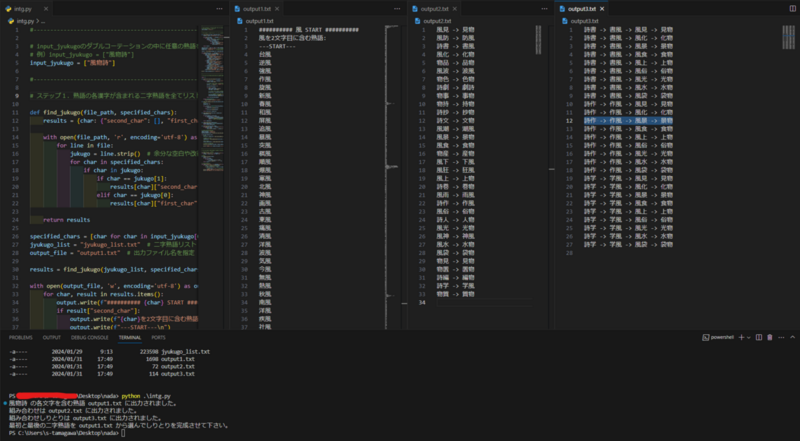
Main.pyは主に3つの処理で構成されていて、実行するとそれぞれoutput1から3の3つのテキストファイルが生成されます。
ステップ1:output1.txt
最初の処理は、入力された任意の三字熟語について、各漢字を含む二字熟語を、jyukugo_list.txtから選抜します。
これらはoutput1として書き出されます。
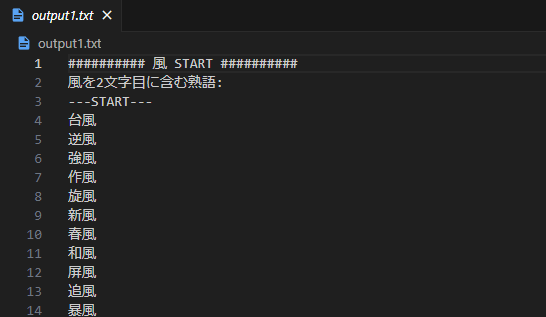
ステップ2:output2.txt
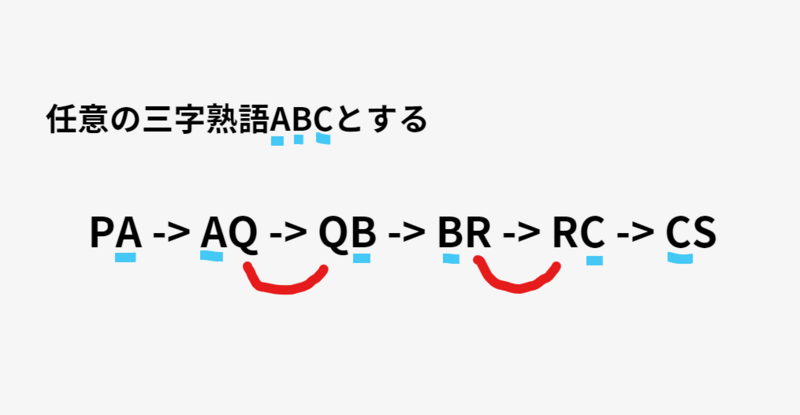
次のステップは、output1で書き出された二字熟語から、上図のAQ-QB、BR-RCとなりえるしりとりの組み合わせが存在するか探します。
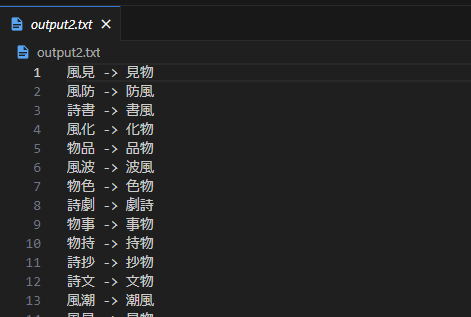
存在しなければ空になります。
ステップ3:output3.txt
最後のステップは、output2の組み合わせを更に組み合わせて、しりとりを作ります。
できたしりとりを文字列として、任意の三字熟語ABCが文字列内にあるかどうかチェックします。
該当しない場合は空となります。
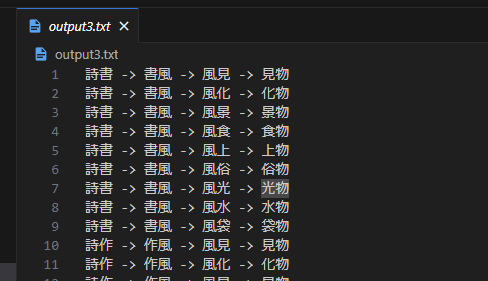
output3が出力されたら、最初と最後の二字熟語(上図でいうとPAとCS)をくっつければ完成です。
候補はoutput1から選べば簡単です。
出題したい三字熟語によっては、output3が空になることはありますが、output1や2の情報をヒントに、漢字を追加することでしりとり作問は省力化できるはずです。
※output2が空になる熟語の場合は、作問が厳しい気がします。
Main.py
筆者はPython3.10.11を使用しています。
#------------------------------------------------------------------------- # input_jyukugoのダブルコーテーションの中に任意の熟語を入れる # 例)input_jyukugo = ["風物詩"] input_jyukugo = ["風物詩"] #------------------------------------------------------------------------- # ステップ1.熟語の各漢字が含まれる二字熟語を全てリストアップ > output1.txt def find_jukugo(file_path, specified_chars): results = {char: {"second_char": [], "first_char": []} for char in specified_chars} with open(file_path, 'r', encoding='utf-8') as file: for line in file: jukugo = line.strip() # 余分な空白や改行を削除 for char in specified_chars: if char in jukugo: if char == jukugo[1]: results[char]["second_char"].append(jukugo) elif char == jukugo[0]: results[char]["first_char"].append(jukugo) return results specified_chars = [char for char in input_jyukugo[0]] # 各文字をリストに分解 jyukugo_list = "jyukugo_list.txt" # 二字熟語リスト output_file = "output1.txt" # 出力ファイル名を指定 results = find_jukugo(jyukugo_list, specified_chars) with open(output_file, 'w', encoding='utf-8') as output: for char, result in results.items(): output.write(f"########## {char} START ########## \n") if result["second_char"]: output.write(f"{char}を2文字目に含む熟語:\n") output.write(f"---START---\n") for jukugo in result["second_char"]: output.write(f"{jukugo}\n") output.write(f"---END---\n") if result["first_char"]: output.write(f"{char}を1文字目に含む熟語:\n") output.write(f"---START---\n") for jukugo in result["first_char"]: output.write(f"{jukugo}\n") output.write(f"---END---\n") if not result["second_char"] and not result["first_char"]: output.write(f"---none_START---\n") output.write(f"{char}を含む熟語は見つかりませんでした。\n") output.write(f"---END---\n") output.write(f"########## {char} END ########## \n") print(f"{input_jyukugo[0][0:]} の各文字を含む熟語 {output_file} に出力されました。") #------------------------------------------------------------------------- # ステップ2.リストアップからしりとりができる組み合わせを重複無しでリストアップ > output2.txt import re def extract_all_two_char_phrases(file_path): try: with open(file_path, 'r', encoding='utf-8') as file: content = file.read() # ---START---から---END---の範囲を正規表現で抽出 matches = re.finditer(r'---START---(.*?)---END---', content, re.DOTALL) all_two_char_phrases = [] for match in matches: start_index = match.start(1) end_index = match.end(1) # ---START---から---END---の範囲内のテキストを取得 phrases_text = content[start_index:end_index] # 二字熟語を正規表現で抽出して配列に追加 two_char_phrases = re.findall(r'\b\w{2}\b', phrases_text) all_two_char_phrases.append(two_char_phrases) return all_two_char_phrases except FileNotFoundError: print("ファイルが見つかりません。") def split_and_combine_lists(two_char_phrases_lists): # 分割 first_list = [] second_list = [] for i, phrases in enumerate(two_char_phrases_lists): if i % 2 == 0: second_list.extend(phrases) else: first_list.extend(phrases) return first_list, second_list def find_combinations(first_list, second_list): combinations = [] for first_phrase in first_list: for second_phrase in second_list: if first_phrase[1] == second_phrase[0]: combinations.append((first_phrase, second_phrase)) break # 一致したら次の要素を確認する必要はないので、ループを抜ける return combinations def remove_duplicates(combinations): unique_combinations = list(set(combinations)) return unique_combinations def write_to_file(file_path, data): with open(file_path, 'w', encoding='utf-8') as file: for item in data: file.write(f"{item[0]} -> {item[1]}\n") # ファイルパスを指定して実行 input_file_path = 'output1.txt' output_file_path = 'output2.txt' two_char_phrases_lists = extract_all_two_char_phrases(input_file_path) if two_char_phrases_lists: # 分割 first_list, second_list = split_and_combine_lists(two_char_phrases_lists) # 組み合わせの検索 combinations = find_combinations(first_list, second_list) # 重複の削除 unique_combinations = remove_duplicates(combinations) # ファイルへの書き込み write_to_file(output_file_path, unique_combinations) print(f"組み合わせは {output_file_path} に出力されました。") #------------------------------------------------------------------------- # ステップ3.重複無しの組み合わせで繋がる且つinput_jyukugoが含まれてるかチェック # ファイルからデータを読み込む with open('output2.txt', 'r', encoding='utf-8') as f: strings = [line.strip() for line in f] # 処理1 def connect_strings(strings): result = [] for s1 in strings: for s2 in strings: if s1 != s2 and s1[-1] == s2[0]: result.append(s1 + ' -> ' + s2) return result # リストの要素を走査 with open('output3.txt', 'w', encoding='utf-8') as f: # 出力ファイルを開く for result in connect_strings(strings): # 3つの漢字が全て含まれるか確認 if input_jyukugo[0][0] in result and input_jyukugo[0][1] in result and input_jyukugo[0][2] in result: # 出力 f.write(result + '\n') # ファイルに書き込む print(f"組み合わせしりとりは output3.txt に出力されました。") print(f"最初と最後の二字熟語を output1.txt から選んでしりとりを完成させて下さい。")
オマケ
Python環境をローカルで作れない/面倒な場合は、Paiza Cloudなどのオンライン開発環境がとても便利です。
会員登録は必要ですが、立ち上げてすぐに使えます。
paiza.cloud
output3まで行かなくても、漢字しりとりの作問は劇的に楽になるはず。
楽しい作業でした。